線上影音
Home > ANSYS Designer 教學 > DDR4 and Compliance Test
本文始於2017.07,目標是介紹DDR4的設計與模擬挑戰,並示範SIwave如何做DDR4的暫態眼圖、SSN、on-die de-cap影響、DBI耗電分析與Compliance Test。The article started in 2017.07. It is intended to introduce DDR4 design and simulation challenges. It demonstrates DDR4 transient EYE, SSN, on-die de-cap effect、DBI power consumption analysis and compliance test with R18.2 SIwave (SIwave2017.2 ,Designer circuit).
-
The difference between DDR4 and DDR3
-
DDR4 Design Challenges
-
DDR4 Simulation Challenges
3.2 使用IBIS 5.0 power aware model
-
DDR4 3200 Simulation
-
問題與討論Q&A
6.3 QuickEYE與VerifyEYE真的比Transient EYE快嗎?
6.4 DDR4 Virtual compliance test是如何以transient analysis結果得到BER=1e-16下的眼高與眼寬? (重要)
![]()
-
The difference between DDR4 and DDR3
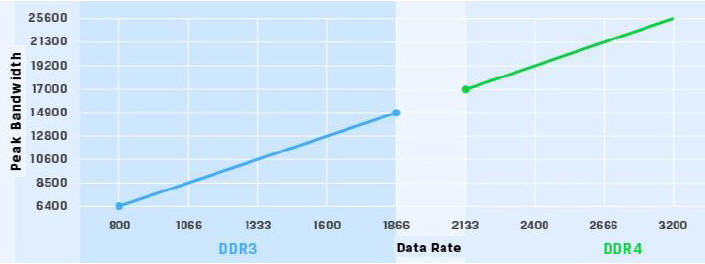
1.1 DDR4傳輸速度與頻寬增加
DDR3 1600/1866MHz,DDR4 2133/3200MHz
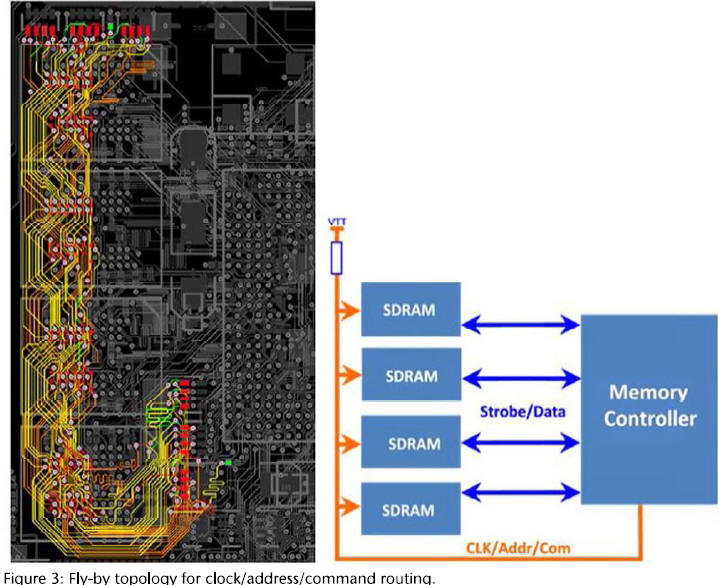
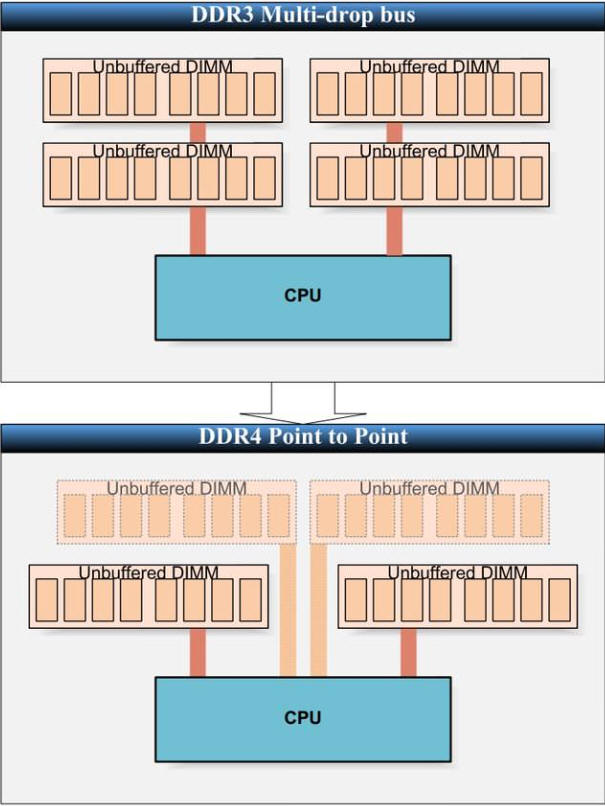
DDR3採用多點分支單流架構,DDR4採用點對點傳輸架構。[1] (DDR4 3200MHz,資料傳輸頻寬高達 25.6GB/s)
DDR3採用了大水庫理論,所有資料集中到一根大水管後送出。而DDR4則採用點對點分流架構,當每一條水管流量都很大時,累加起來的流量會超過單一條大水管,能避免單條通道傳輸頻寬的瓶頸拖慢整體效能。
現在DDR4大部分還是採用2SPC (2 Slot per Channel)或稱2DPC (2 DIMM per Channel)的架構,2017 Q1最新的Intel® Core™ i7-7920HQ處理器,最快支持到DDR4 2400MHz;開發中的2666/3200MHz也是採用2SPC傳輸架構。
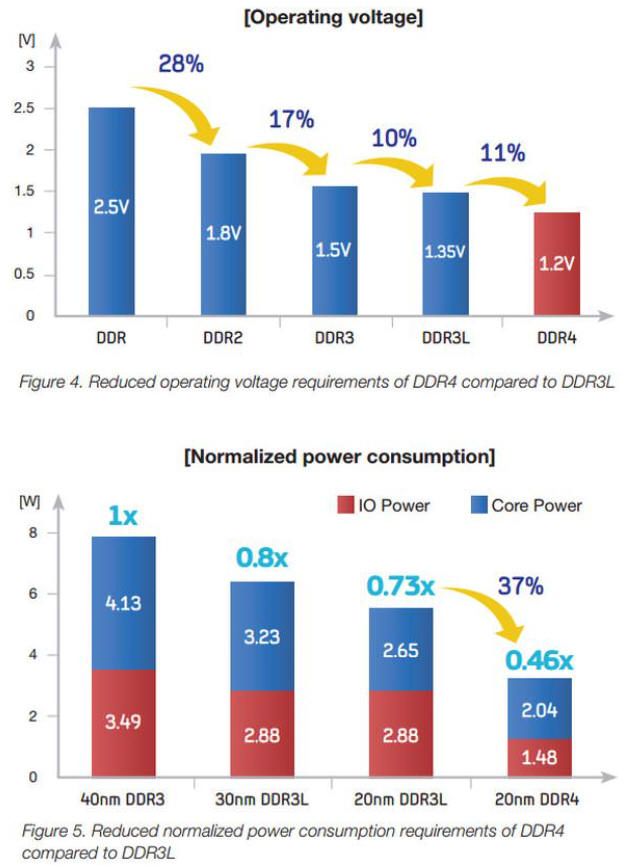
1.2 DDR4更省電
操作電壓降低:DDR4(1.2V), DDR3(1.5V)。除了降低工作電壓,LPDDR4支援深度省電模式(DPD, Deep Power Down Mode),DDR4支持Max Power Saving Mode,在暫時不需要用到記憶體的時候可進入休眠狀態,可進一步減少待機時功率的消耗。
DDR4搭載了溫度自更新回饋機制(TCSE,Temperature Compensated Self-Refresh),能夠降低晶片在自動更新時所需耗費的電力,同時,還導入了資料匯流反轉機制(DBI,Data Bus Inversion),使得VDDQ電流量得到有效控制。[1],[2],[9]p.20,[14]p.6
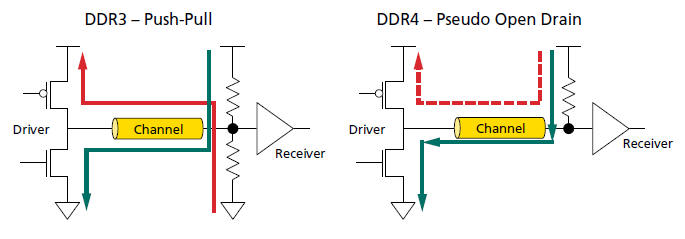
DDR4使用POD(Pseudo Open Drain)介面,用以減少I/O電源消耗量。[14]p.3
對DDR4的IO來說,drive high時幾乎不耗電的(下圖右的紅色虛線電流路徑),這就是為何採用DBI+POD機制具有優勢的原因[3]p.15,[9]p.80
1.3 DDR4高速訊號傳輸技術
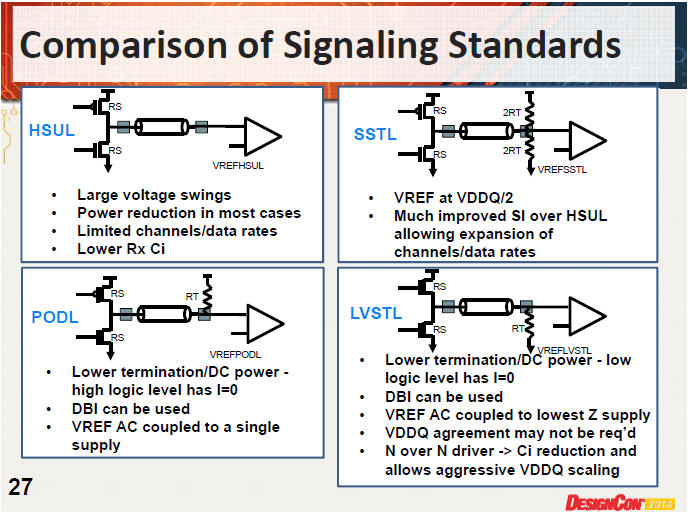
-- IO技術不同 :DDR3採用SSTL,Vref=VDDQ/2;DDR4採用PODL,Vref不是固定的,會隨VDDQ的AC變動而變動Vref=((2Rs+Rt)/(Rs+Rt))*VDDQ/2. [9]p.18/25/27
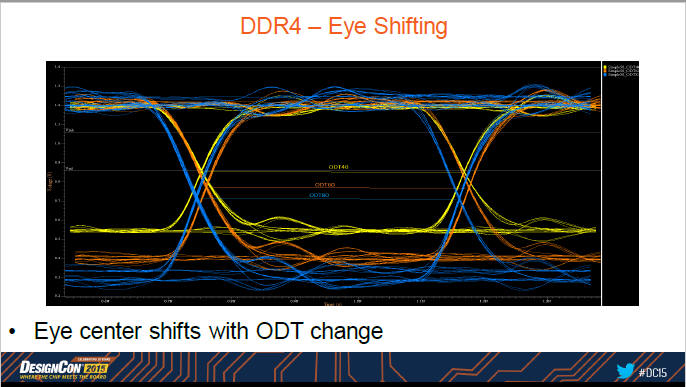
-- ODT眼圖特徵不同[14]p.13-14
請注意下圖是DQ的眼圖,而不是DQS pair的眼圖,前者DDR4眼圖的crossover中心才會隨ODT強度而變化
-- DDR4增加了DBI(Data Bus Inversion)、CRC(Cyclic Redundancy Check)、CA parity等功能,讓DDR4記憶體在更快速與更省電的同時亦能改善資料傳輸及儲存的可靠性。[2],[9]p.20,[14]p.6
-- 對於2933/3200的支持,CPU/DIMM在DQ上都增加了EQ (CTLE),但是CAC (Command/Address/CTL)上,暫時還沒有EQ,雖然其速率比DQ低,但是在DIMM卡上Diasy Chain 的結構 CTL有9 loads,Command/Address有36個loads,所以CAC的高速設計,對於UDIMM和SODIMM來說,更是一個很大的挑戰。對於CAC,目前都是在DIMM最末端用電阻端接到Vtt來做終端 。
1.4 其他 [1][2]
DDR4 新增了4 個Bank Group 資料組的設計,Bnak Group可以選擇2個或4個獨立分組,而DDR4模組內的每單位Bnak Group都可獨立進行讀取、寫入、喚醒及更新等動作。Bank Group 資料組可套用多工的觀念來想像,亦可解釋為DDR4 在同一時脈工作周期內,至多可以處理4 筆資料,效率明顯好過於DDR3。又DDR4 雖然增加記憶體組數(bank)為 16,但卻加入記憶體群組(bank group)的限制。不同 bank 但若屬於同一個 bank group,連續讀寫指令間必須增加等待時間週期,造成資料匯流排的閒置機率升高,傳輸效能降低。在此種限制下,如何充分利用資料匯流排以達成最高效率,對於控制 DDR4 的邏輯電路設計是新的挑戰。
由於以上因素,DDR3與DDR4不能混用(工作電壓與防呆插槽的設計都不同)


-
DDR4 Design Challenges

DDR4的設計挑戰,其實與DDR3雷同,只是速度更快,設計要求更高。早從DDR3時代開始,從主控IC->PCB->記憶體整條通道,基於"3D結構"的角度考慮通道間耦合(inter-channel coupling)、因為迴路(return path)的影響考慮封裝的ball map與ball下方的slot、SI+PI的模擬...。[7]
以下是一個欠佳的設計範例
以下是優化後的設計範例
2.1 3D封裝(SiP,PoP,TSV,InFO)
2.1.1 Traditional 3D Packaging Technologies:SiP and PoP , [9]p.46-47
2.1.2 New TSV based 3D Packaging Technologies:For Wide IO DRAM and High Bandwidth Memory
TSV矽穿孔技術因為成本高,良率與散熱問題不易處理,有興趣的人請自行參考資料[9]p.54~,[21]
2.1.3 TSMC's InFO (Integrated FanOut) [21]
一般的Fan-Out技術
TSMC的Fan-Out技術
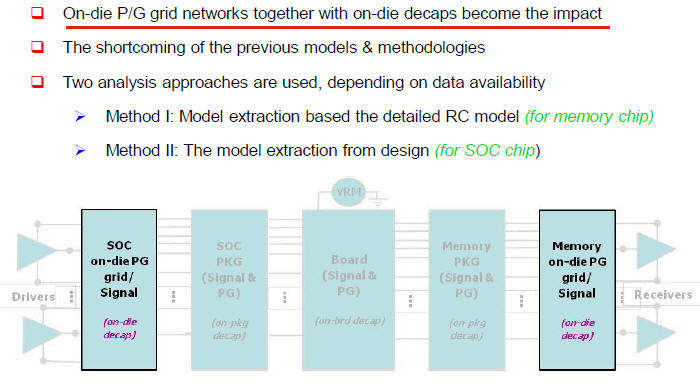
2.2 PI optimize for IC
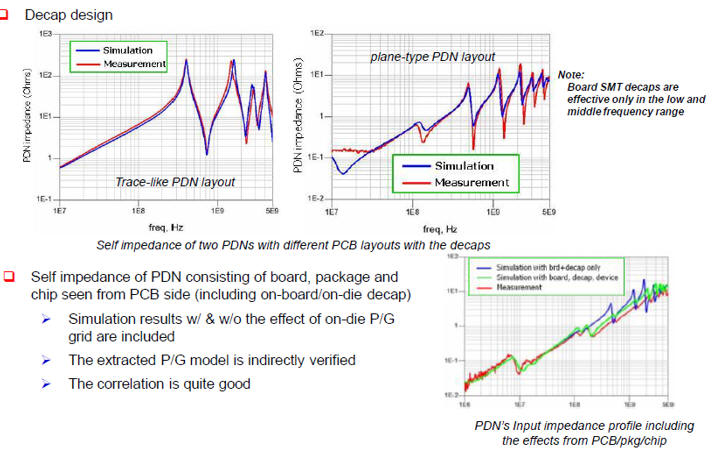
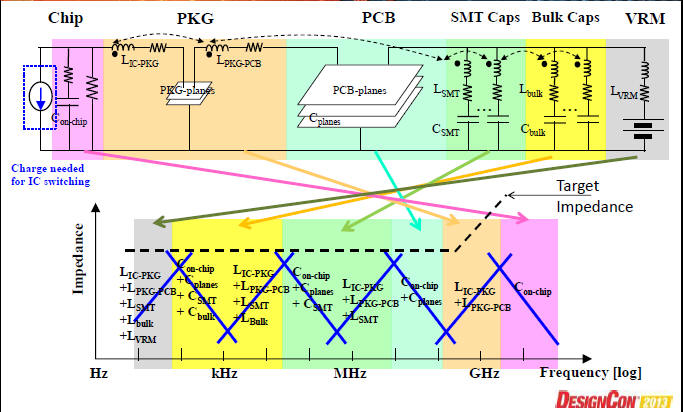
早從DDR3時代開始,on-die de-cap擺放的大小,已經成為速度上不上的去的關鍵。[8]p.4
記得數年前剛從DDR2轉DDR3的年代,幾家國內知名的IC設計公司,明明已經打開過別人IC看過,裏面就是放一堆on-die de-cap,但就是不願意把on-die de-cap加大,被cost-down的死腦筋卡關,拼命想著如何在封裝與PCB層級內改善,最後還是徒勞無功。唉...這樣的例子在業界屢見不鮮。
Micron DDR4甚至直接告訴你他on-die電容放多少(寫在IBIS\SPICE quality report內),真是佛心來的。大廠的風範與格局就是不同
2.3 PI optimize for System
如果從IC->封裝->PCB都有抽取model正確的考慮,模擬的準確度是非常高的,不論是高速訊號或是EMI干擾的問題都可以有效分析 [8]p.2
百MHz的de-cap靠PCB疊構的設計,在P/G層之間夾出的寄生電容,而GHz以上的de-cap必須要靠on-die de-cap. [22]
2.4 SI optimize for System
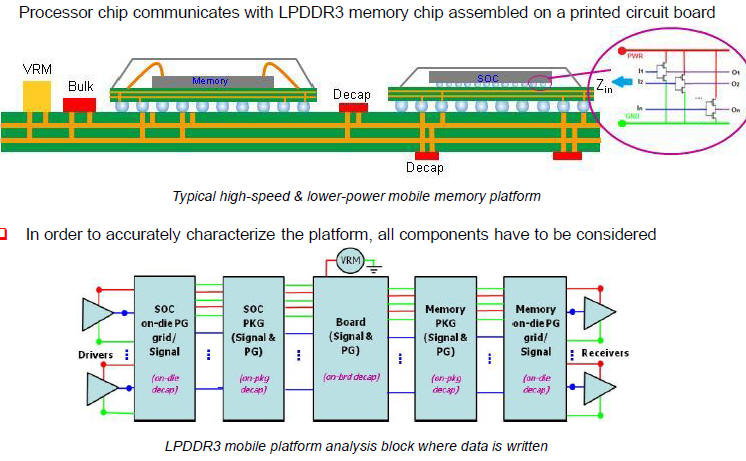
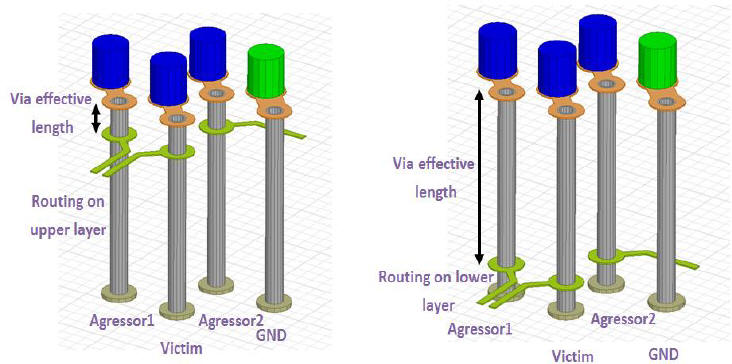
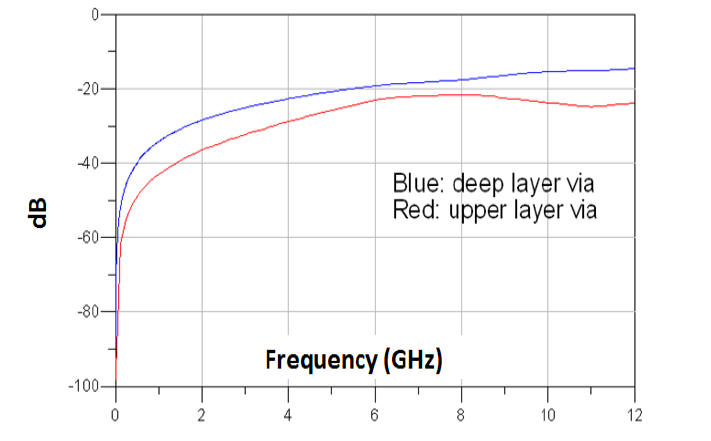
2.4.1 在DesignCon2013由Samsung所發表的LPDDR3優化設計[7]p.17,與在DesignCon2015由Xilinx所發表的DDR4 2400優化設計中[15]p.12,我們不約而同地看到了選擇via導通長度較短(shorter via effective length, but longer via stub)的設計,得到較好的DDR SI特性。
在Via Stub Effect 8,7中,我們有說明:via barrel結構上,訊號經過的部份(via effective length)貢獻串聯電感效應,而訊號沒經過的部分(via stub)貢獻電容效應,這兩者是相互trade-off的。基於不同的板厚與傳輸速度頻寬考慮,有時是以短的via effective length)較佳,有時則以短的via stub較佳。
2.4.2 減少因訊號換層引起的迴路不連續 -- add de-cap [4]p.39
2.4.3 DDR4 3200,甚至DDR5的DQ都還是維持以單端訊號(Single-end)的方式傳送,如何減少crosstalk也是很關鍵
減少訊號線走線間的crosstalk -- keep space enough [4]p.37 (保持2~3W比起插入grounding guard trace在layout空間上較可行)
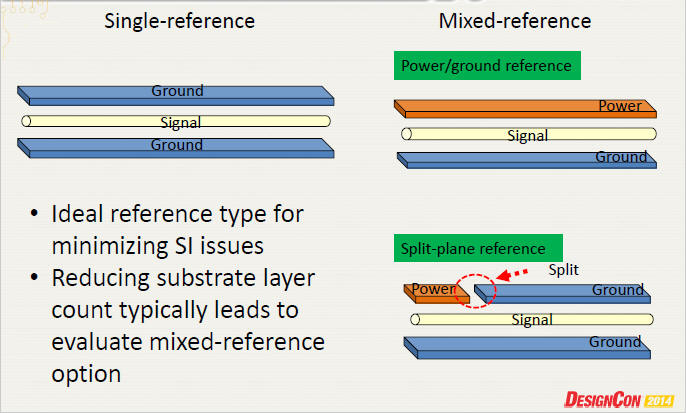
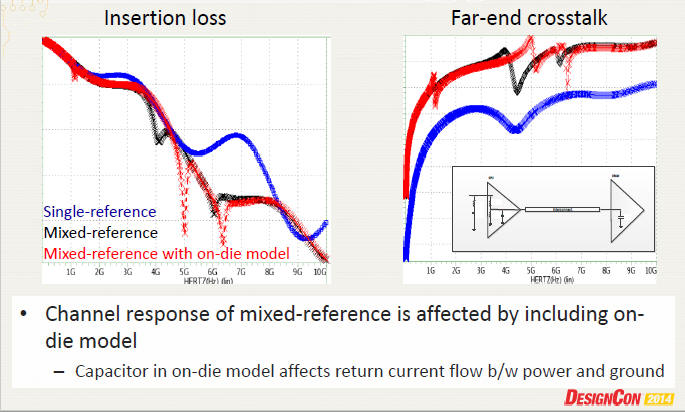
減少因跨地引起的crosstalk [11]
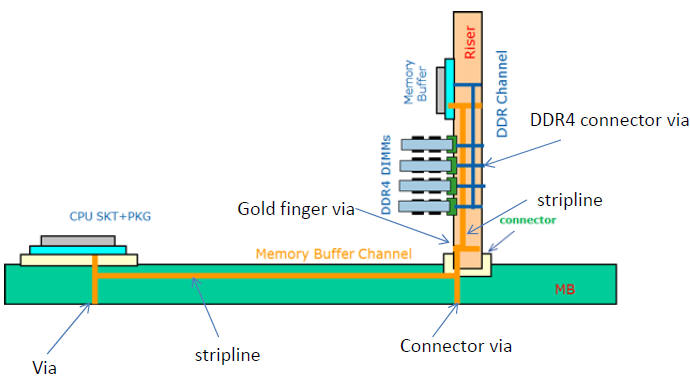
減少DIMM connector與memory buffer routing間的crosstalk [5]p.9 -- add ground vias beside pads of connector

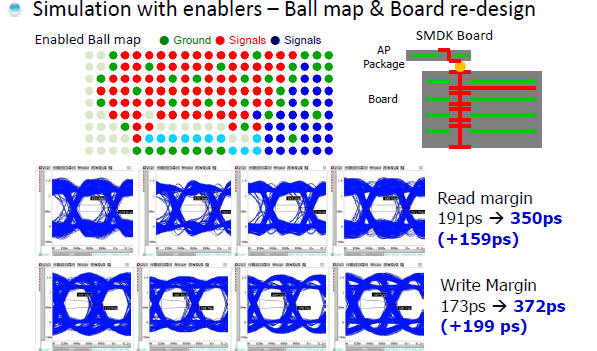

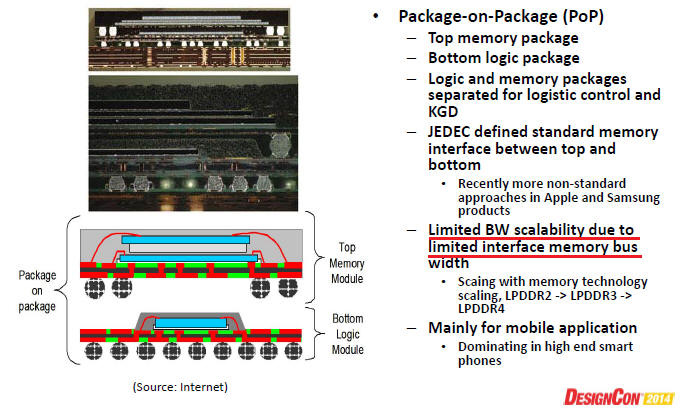
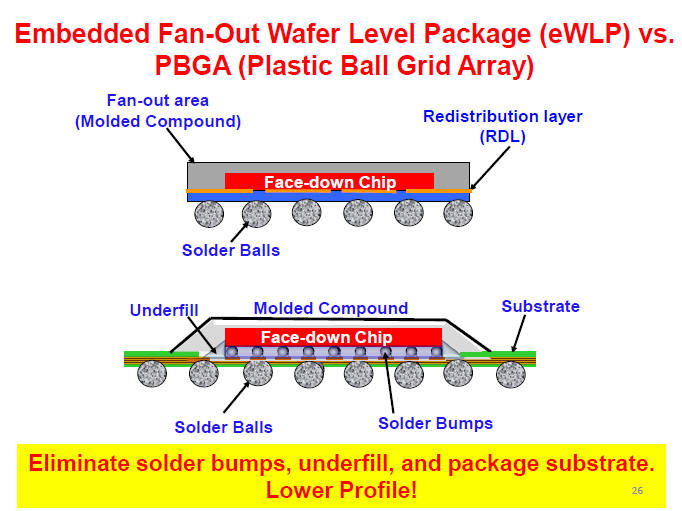




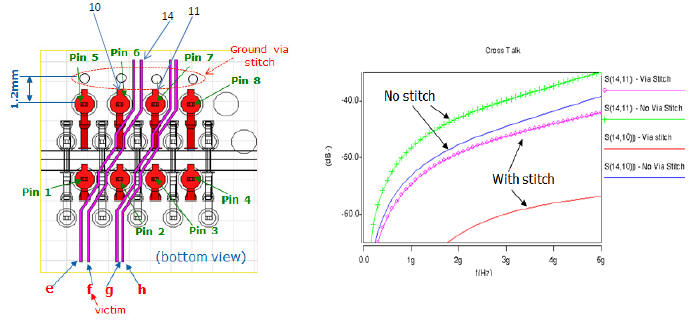
-
DDR4 Simulation Challenges
3.1 使用Touchstone®v2.0 [12]
TS2.0 (.ts)支持mixed reference impedance,而TS1.0 (.snp)每個port的reference impedance都要是相同的(e.g. 50ohm)。refer to here
對模擬軟體來說,針對訊號線設reference impedance=50,P/G nets設reference impedance=0.1 ohm,會有助於模擬收斂。refer to here
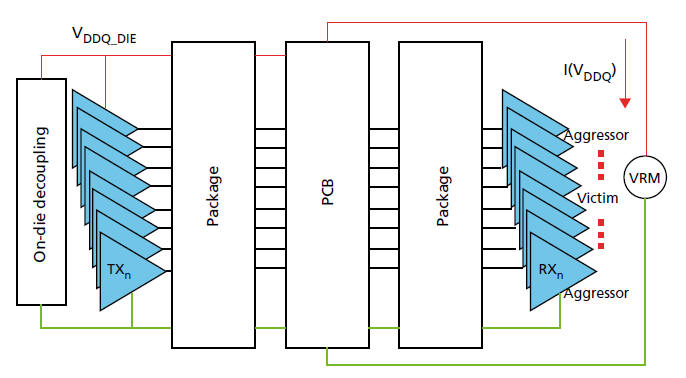
3.2 使用IBIS 5.0 power aware model [14]
美光的文件[23]說明提供IBIS 5.0 power aware model,供做DDR4 PI以及SSO模擬,這些模型內涵[Composite Current] Data,可以讓模擬更準確。美光是業界做IBIS model做得非常好的典範,也感謝其在官網大方分享DDR4 IBIS\SPICE model。
MT40A512M16JY-075E , MT40A1G8WE-083E
3.3 使用Statistical-based analysis [13][18]
DDR4要求BER=1e-16下的規格,通過使用IBIS power aware model與Statistical-based analysis,可以有效的評估DDR4設計優劣
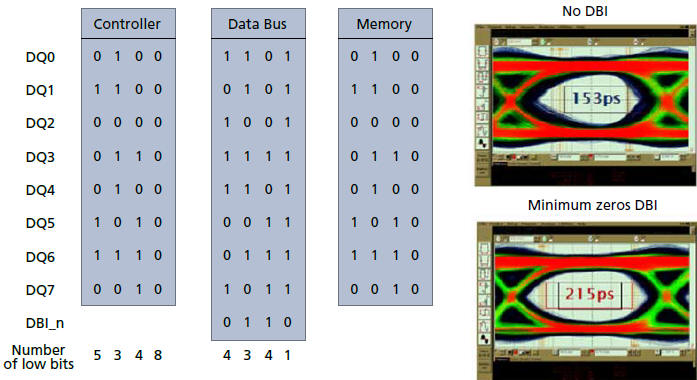
3.4 Random bit pattern with DBI coding [3]p.6
DBI是DDR4一個非常關鍵的省電技術,直接會影響暫態電流與 眼圖的模擬結果,這需要整個byte (8 bits)一起考慮。目前的方法先把整組random bit pattern整理過,再餵給circuit simulator。
-
DDR4 3200 Simulation
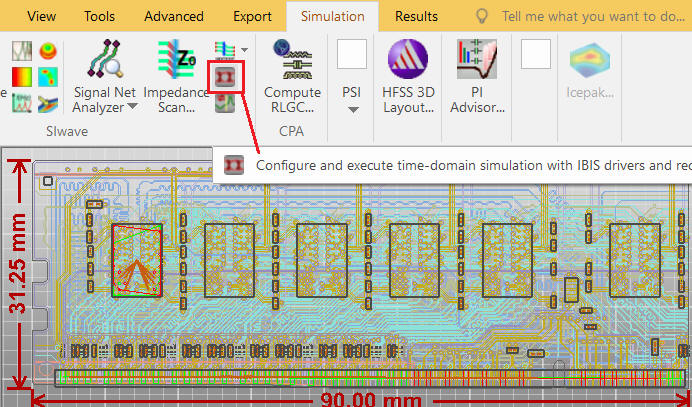
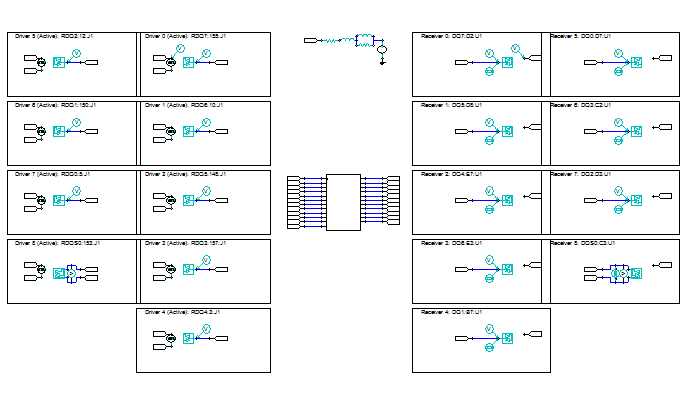
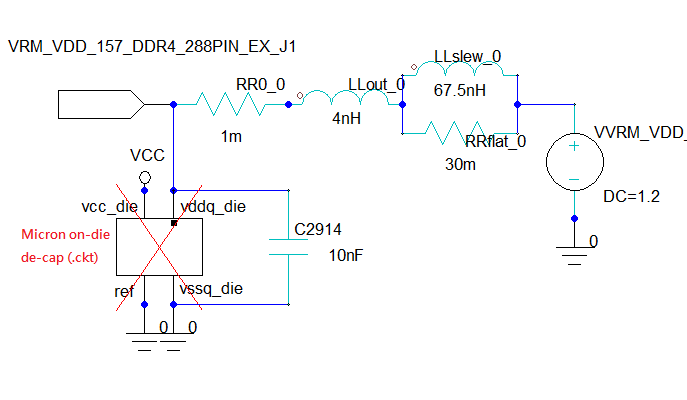
使用美光DDR4 MT40A512M16JY-075E (IBIS 5.0 power aware model),配合SIwave2017.1內的SIwizard功能自動在Designer內產生電路,自動連結SIwave內的DDR4真實DIMM model,做DDR4 3200的模擬分析。
下圖所有的電路連結(DQ single-end, DQS differential pair),以及上圖在SIwave中做pin group與下port,不管是signal nets for SI或P/G nets for PI,所有連接與設定工作都是自動完成。PCB與電路範例
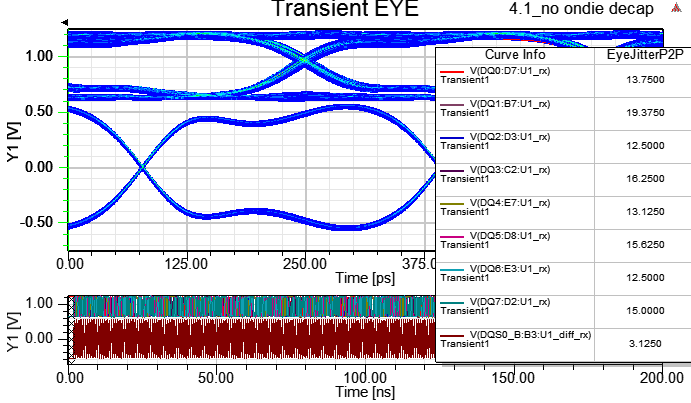
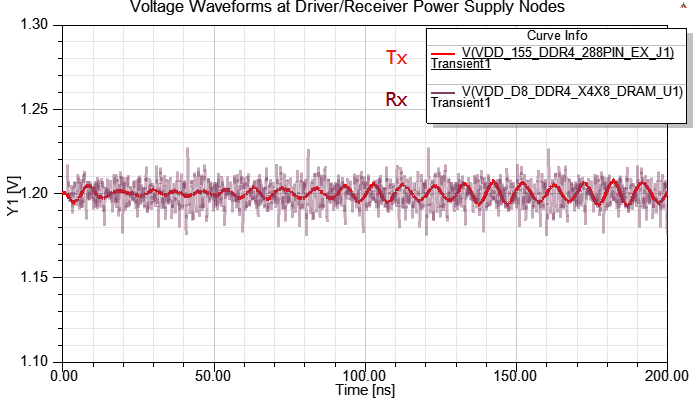
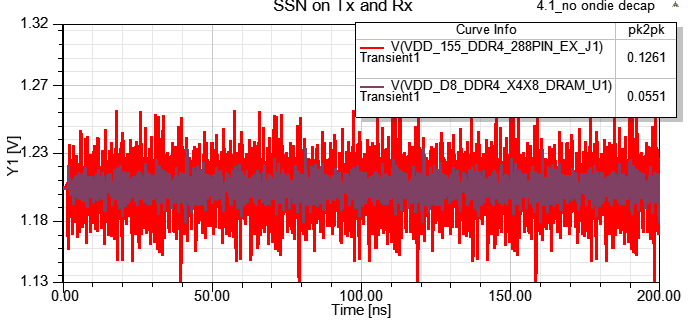
4.1 no on-die de-cap
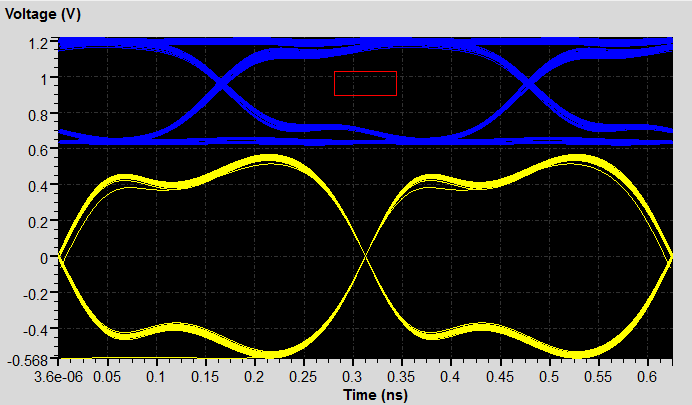
下圖是DDR4 3200MHz DQ[0:7] and DQS pair (all with ODT48),可以清楚的看到有開啟ODT時,DQ眼圖中間交叉點位置會上移,但訊號高準位維持在1.2V,但DQS差動訊號則的眼圖交叉點則是維持在0V。DQS的jitter比DQ小是因為灌clock pattern,其他DQ則灌PRBS pattern。
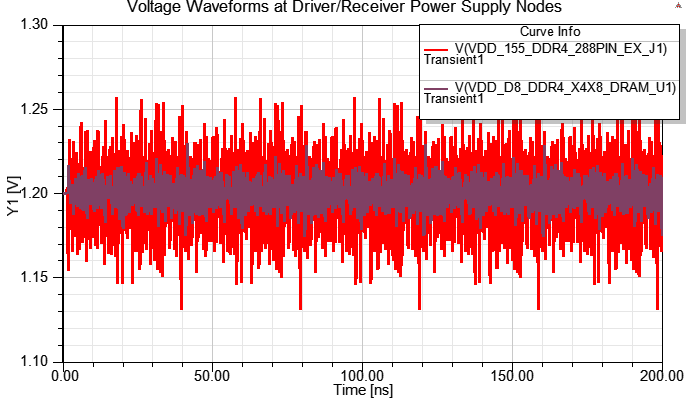
4.2 on-die de-cap at TX
如果在Tx端VRM加on-die de-cap 10nF,會看到Tx端SSO of P/G明顯變好,而這10nF是參考美光的IBIS\SPICE quality report的說明(484pF per DQ pin)。
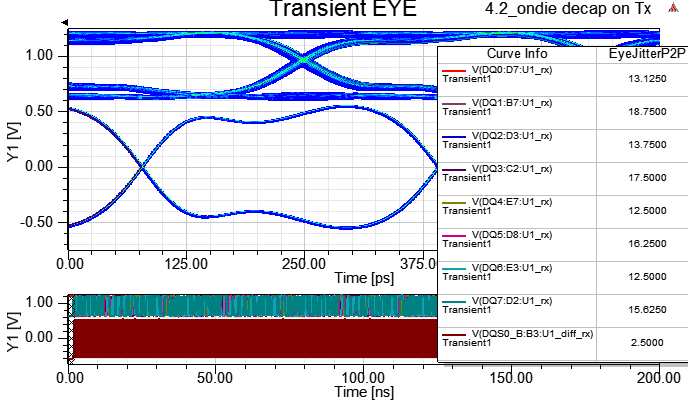
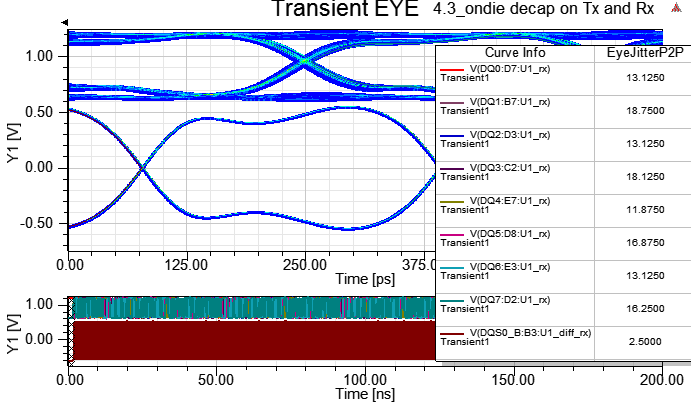
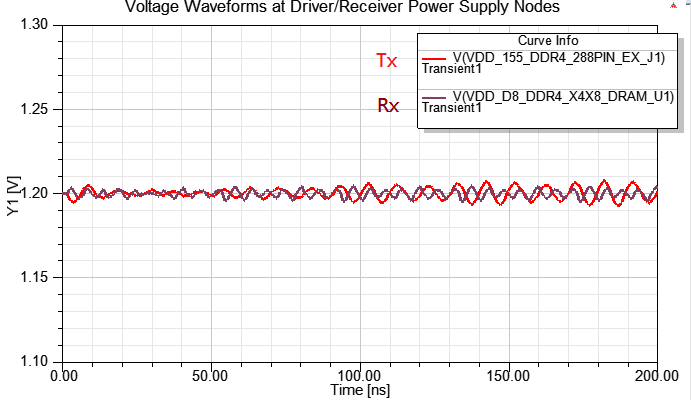
4.3 on-die de-cap at TX and Rx
此例就算Tx與Rx端都掛on-die de-cap,P/G上的SSN有明顯改善,但眼圖的p-p jitter卻沒太大差異,主因是此處的jitter是ISI與DDI引起的,與bit pattern與crosstalk比較有關,PI的影響是其次。
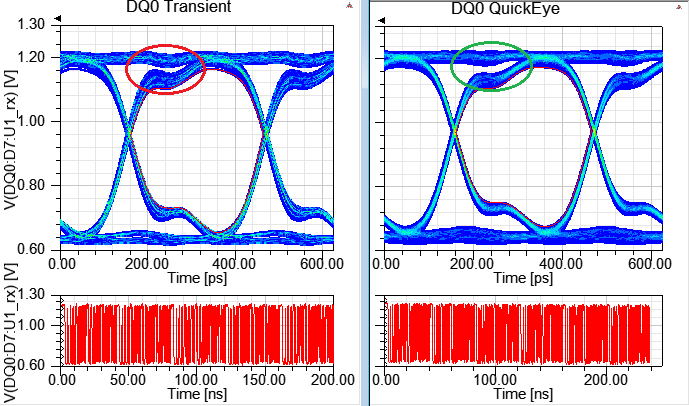
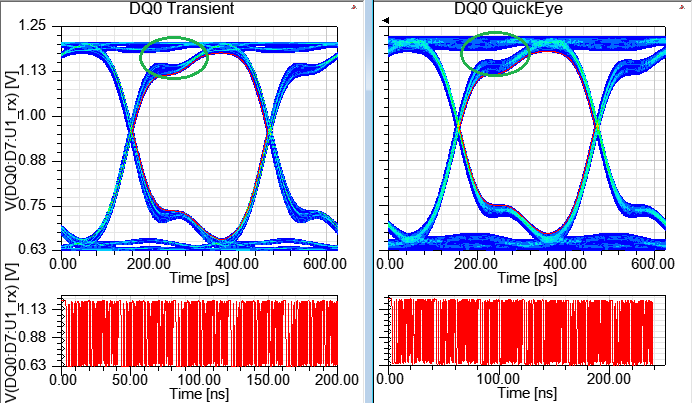
4.4 TransientEYE vs. QuickEYE
從下圖可以看出TransientEYE比起QuickEYE眼圖,在high level的軌跡 略粗一些,這就是SSN貢獻的效應,QuickEYE是看不出來的。
4.4.1 no on-die de-cap
4.4.2 on-die de-cap at Tx and Rx
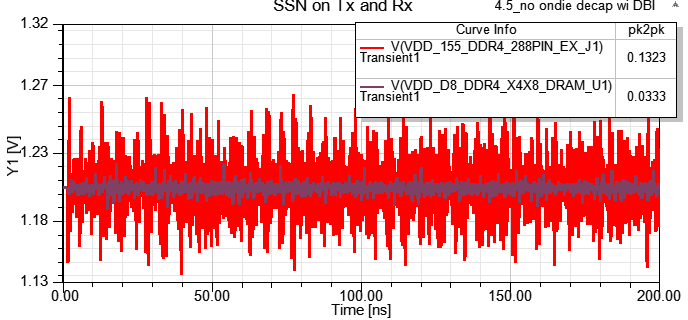
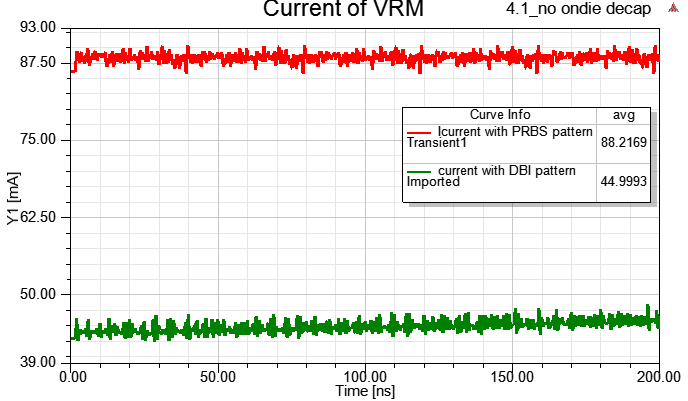
4.5 PRBS vs. DBI patterns
4.5.1 Compare SSN:Rx端的SSN明顯變小
4.5.2 Compare current consumption:current reduction 50%, Amazing!!
5.1 [Circuit] \ [Tool Kits] \ [Virtual Compliance for DDR4]
Virtual Compliance for DDR4是新的功能項目,DDR4 Compliance Test是舊的,建議轉到新的tool kit使用
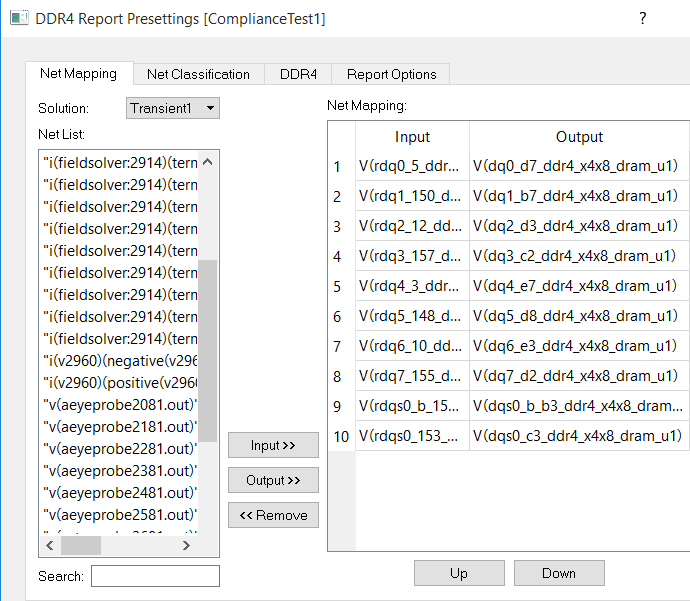
5.2 Presetting dialog for assigning net mapping
Net的In-out的對應連接要正確(可以使用[Up][Down]調整上下位置),軟體會計算self-delay (timing delay)。如果您不需要report self-delay,可以只指定output nets
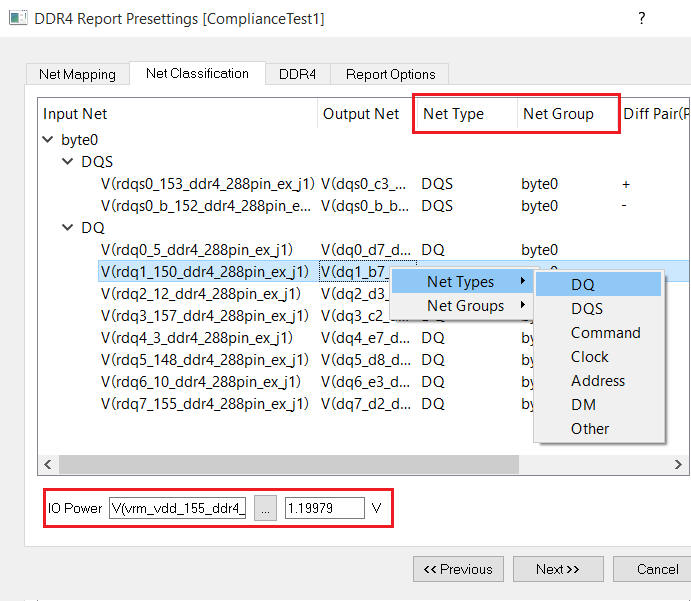
5.3 Net Classification for net type, group and IO power
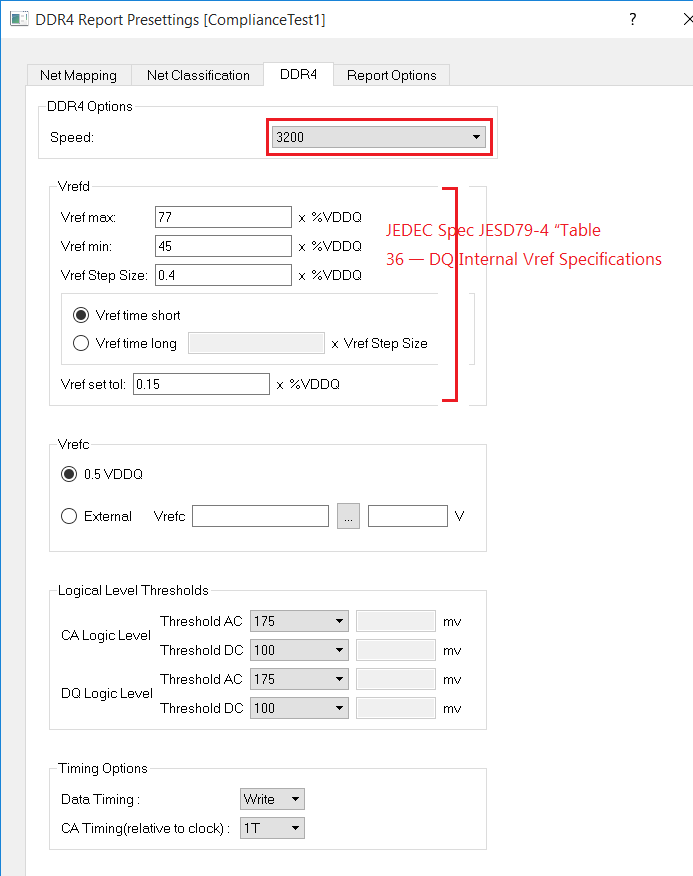
5.4 DDR settings
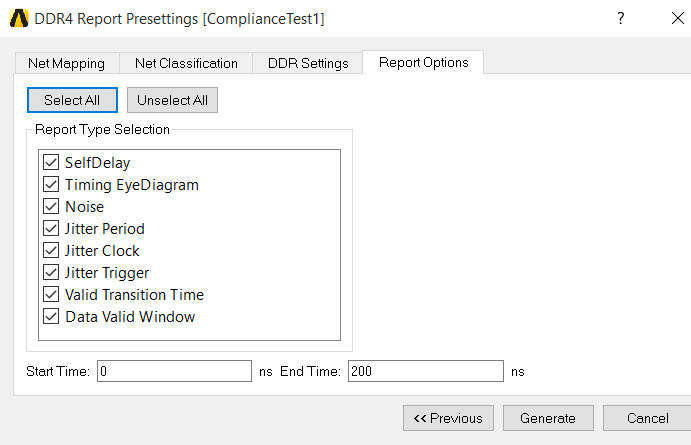
5.5 Report Options
5.6 Self-Delay
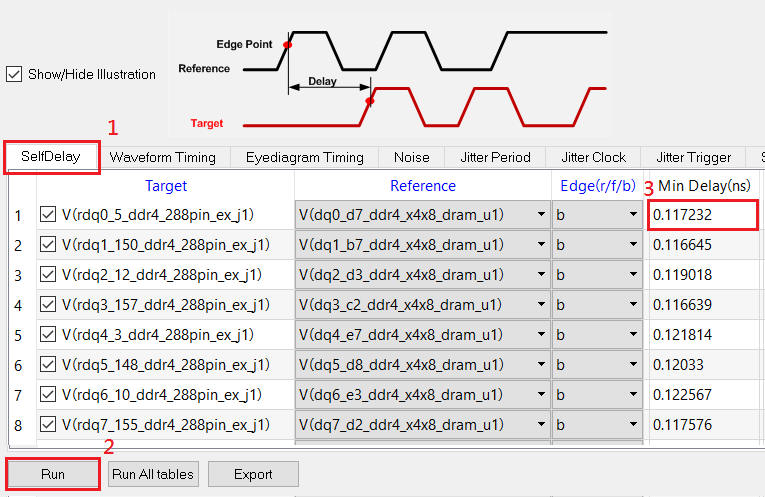
1. Press [Run] to get the reported parameters
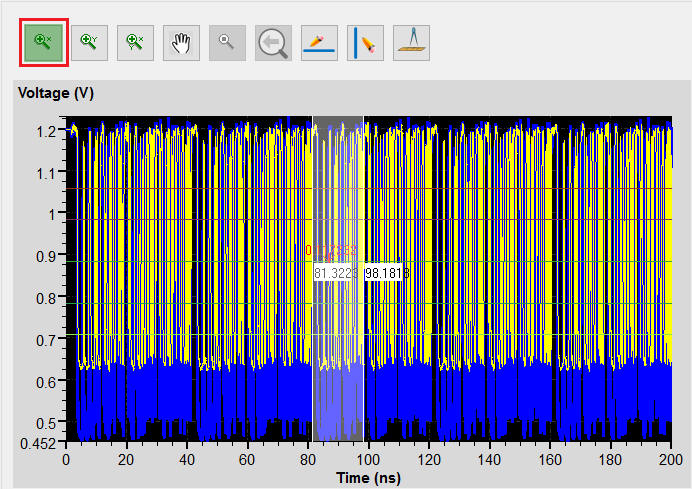
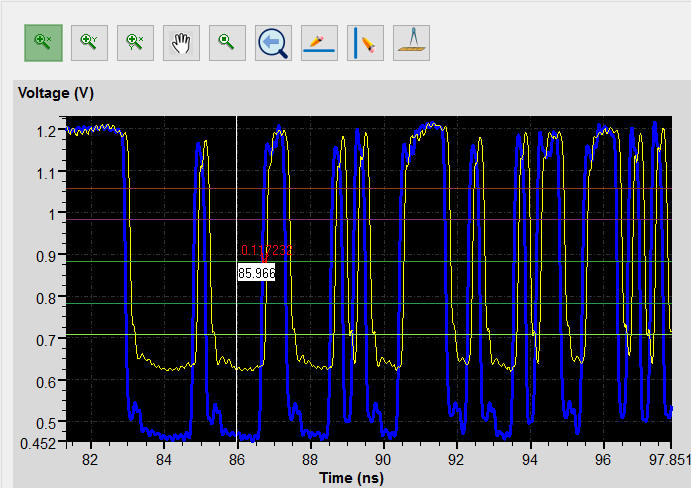
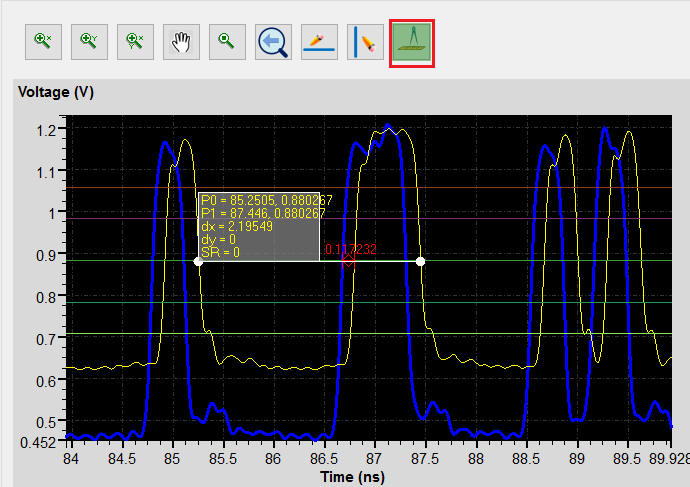
2. Double-click the reported parameters [Min Delay] of DQ0 to open [Waveform Viewer]
3. Measuring function
5.7 Switch to different tabs and press [Run]\[Run All tables] to get other reported parameters.
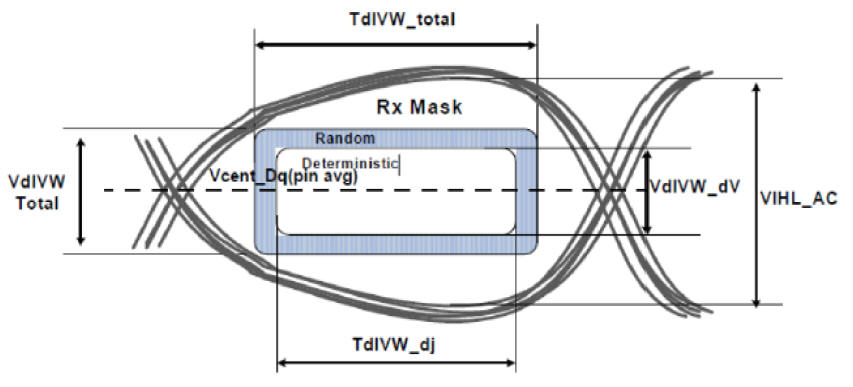
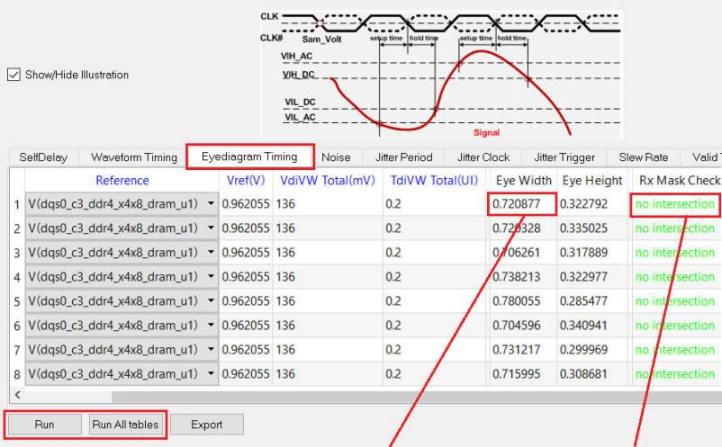
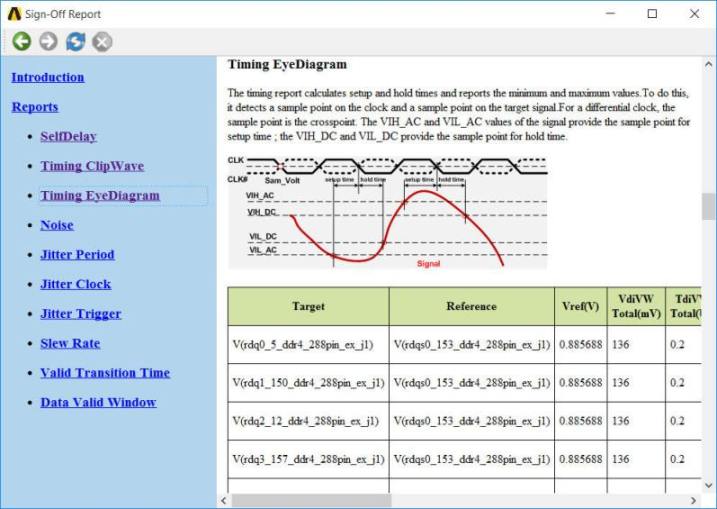
在[Timing EyeDiagram]頁面下,使用者透過輸入[VdiVW Total]與[TdiVW Total]來決定Eye Mask的高與寬,軟體會幫你算出眼圖的參數與是否有碰到Eye Mask (Rx Mask Check)。
For DDR4 compliance, 這裡算出的眼高(Eye High)與眼寬(Eye Width),是在BER=1e-16下得到的值
5.8 Sing-off report
-
問題與討論Q&A
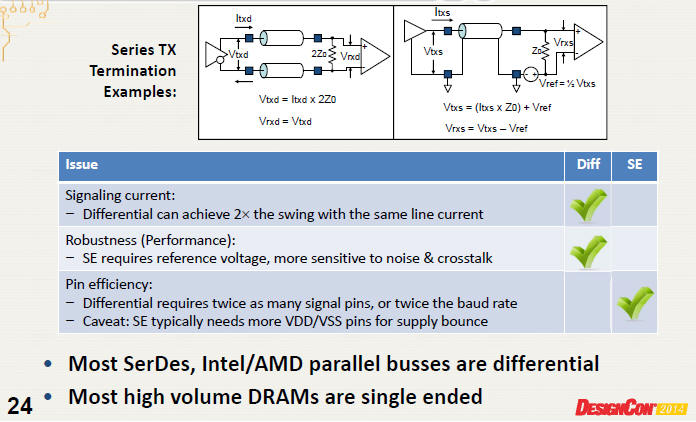
6.1 單端或差動高速訊號設計,其優劣分別為何?
Ans:[9]p.24
6.2 為何市面上目前看不到採用點對點傳輸架構的DDR4?
Ans:我想所需的PCB繞線空間較多, 可支援的總DIMM插槽較少,應該是目前較少人在DDR4使用點對點傳輸架構的主因吧! 比方一顆有6 DDR4 channel的CPU,如果使用點對點架構的DDR接法,最多就接6排DDR4插槽,但如果採用2spc架構,則最多可接12排DDR4插槽。
6.3 QuickEYE與VerifyEYE真的比Transient EYE快嗎?
Ans:這答案很直覺的會以為是"yes",但實際上與模擬條件有關。
如果只跑一個net (e.g. DQ0),且跑1016 bit time,那肯定QuickEYE與VerifyEYE比Transient EYE快許多。
但如果跑八個net (e.g. DQ0~7),且只跑PRBS13 213@104 bit time,那Transient EYE比QuickEYE與VerifyEYE快。關鍵在於QuickEYE與VerifyEYE是by net trigger,模擬的net數越多,模擬時間乘倍數增加。
6.4 DDR4 Virtual compliance test是如何以transient analysis結果得到BER=1e-16下的眼高與眼寬?
Ans:是透過transient analysis數據統計推估出來的,並不是真的跑VerifyEYE。所以transient analysis模擬時間長度會影響step 5.7的眼高與眼寬。
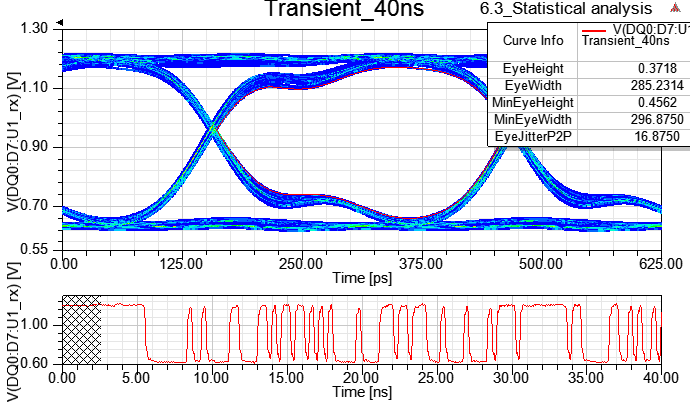
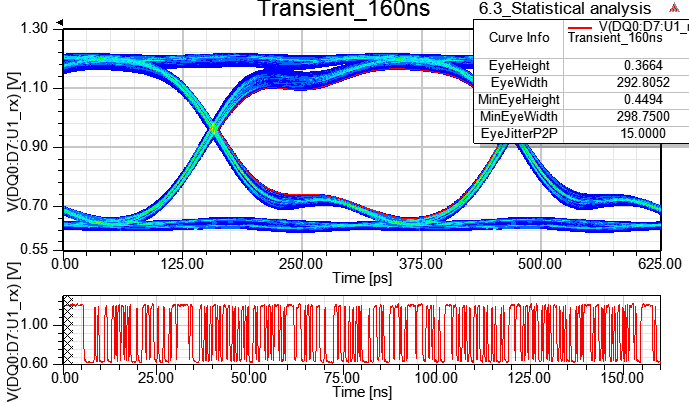
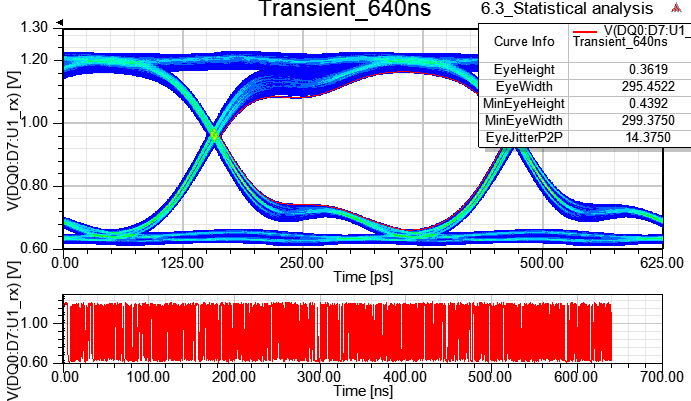
6.4.1 測試Transient EYE跑211 bit (312.5ps*211=640ns)、29 bit (312.5ps*29=160ns)、27 bit(312.5ps*27=40ns)不同的時間長度
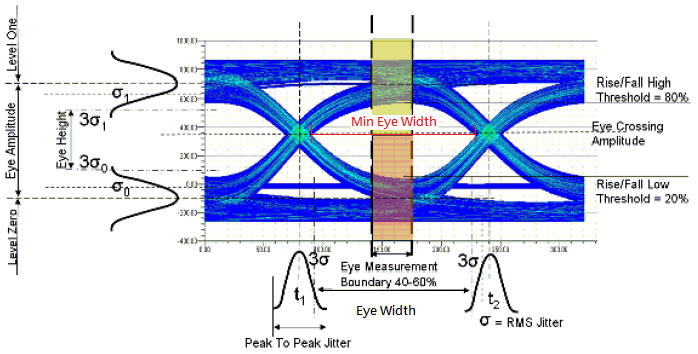
為何always MinEyeHeight>EyeHeight,MinEyeWidth>EyeWidth?
這是user最常問的問題,答案在HELP裡,EyeHeight與EyeWidth是以分佈中心點考慮三倍標準差(3s),是含有統計概念在裡面的。
EyeHeight = [(EyeLevelOne - 3s1) - (EyeLevelZero + 3s0 )] where s1 and s0 are the standard deviations of the vertical histograms used to determine EyeLevelZero and EyeLevelOne.
EyeWidth = [( t2 - 3s) - (t1 + 3s)] where s is the standard deviation of the horizontal histograms used to determine eye-crossing points.
MinEyeWidth is the minimum horizontal opening at the eye-crossing amplitude, typically at the center of the eye. Unlike statistical eye width, if different traces exist for different unit intervals, then MinEyeWidth represents the minimum width of all the traces.
MinEyeHeight is the minimum vertical opening at the eye-measurement point, typically at the center of the eye. Unlike statistical eye height, if different traces exist for different unit intervals, then MinEyeHeight represents the minimum height of all the traces.
6.4.2 當暫態分析的時間太短,可能會得到BER=1e-16下 較差的眼圖參數(眼寬較小、眼高較低)。這背後的物理意義是:暫態分析時間長度較少時(模擬的bit pattern數目較少時),眼圖偏離中間分佈較遠的少數幾次bit pattern在統計上的佔比會升高,導致推估至BER=1e-16下的眼高與眼寬會較worse
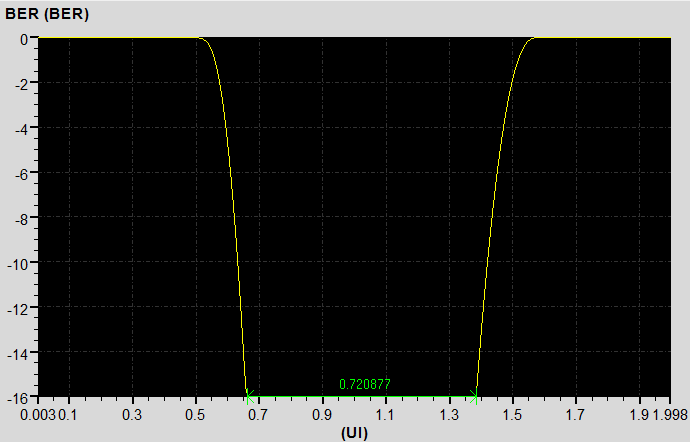
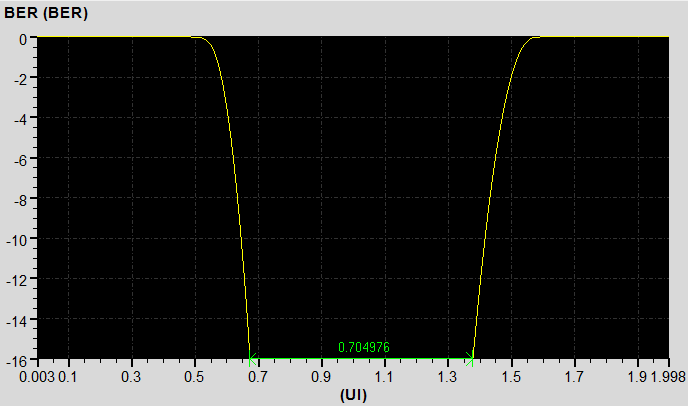
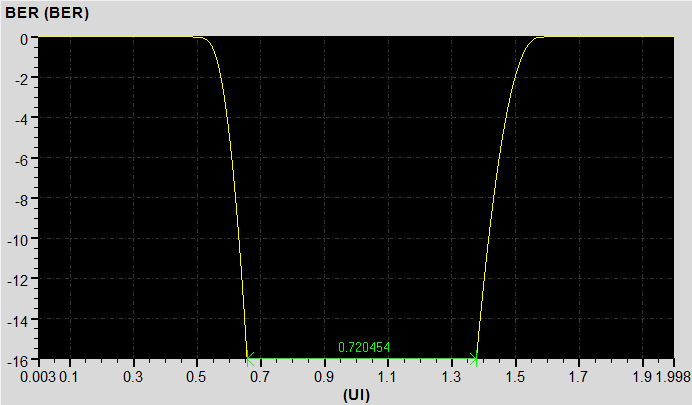
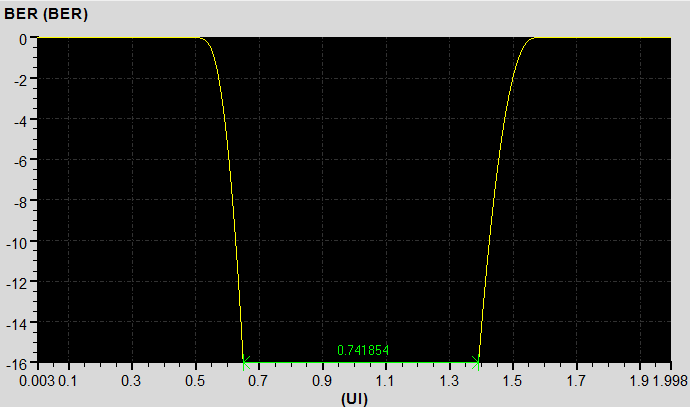
下圖分別顯示不同的暫態分析時間40ns\160ns\640ns下,從DDR4 Virtual compliance test得到BER=1e-16下的Eye Width
暫態分析時間40ns,BER=1e-16下的Rx端眼寬UI*0.704976=312.5ps*0.704976=220.3ps
暫態分析時間160ns,BER=1e-16下的Rx端眼寬UI*0.720454=312.5ps*0.720454=225.14ps
暫態分析時間640ns,BER=1e-16下的Rx端眼寬UI*0.741854=312.5ps*0.741854=231.8ps
-
[1] 記憶體發展簡史
[2] DDR4, DDR3, DDR2, DDR1 及SDRAM各有何不同?
[3] DDR4 Point-to-Point Design Guide
[4] DDR4: Designing for Power and Performance
[5] Xiang Li (Intel), "Channel to Channel Crosstalk Behavior and Design Optimization for DDR4 Signaling", DesignCon 2013. 在connector旁加GND via以降低crosstalk
[6] Jongbae Park (Intel), "DDR Memory Channel Design from Passive Stub Equalizer Perspective", DesignCon2013. 以Stub當被動型EQ
[7] Samsung, "World's First LPDDR3 Enabling for Mobile Application Processors System", DesignCon2013. Re-arrange ball map, signal layer, and tune PoP design ... (推薦)
[8] Samsung, "Power-Signal Co-integrity Design for multi-Gbps Low-Power DDR3 Mobile Platforms", DesignCon2013. on-die decap with ANSYS EBU+SCBU Apache (推薦)
[9] John Eble (Rambus), "An Implementer's Guide to Low‐Power and High‐Performance Memory Solutions", DesignCon2014. (推薦)
[10] Kyoung-Hoi Koo (Samsung), "Versatile IO Circuit Schemes for LPDDR4 with 1.8mW/Gbps/pin Power Efficiency", DesignCon2014.
[11] Seunghyun Hwang (Nvidia), "Mixed-Reference for Optimum Cost & Performance in High-Speed Memory Interface", DesignCon2014. (推薦)
[12] Romi Mayder (Xilinx), "Touchstone®v2.0 SI/PI S-Parameter Models for Simultaneous Switching Noise (SSN) Analysis of DDR4 Memory Interface Applications", DesignCon2014. 強調IO與P/G net在ouchstone®v2.0使用不同的reference impedance收斂性會比較好. IO normalize to 50 ohm, P/G normalize to 0.1 ohm
[13] "Ultrascale DDR4 de-emphasis and CTLE feature optimization with statistical engine for BER specification", DesignCon2015.
[14] "DDR4 Board Design and Signal Integrity Verification Challenges", DesignCon2015. (推薦)
[15] Xilinx, "Ultrascale FPGA DDR4 2400 MT/S system level design optimization and validation", DesignCon2015.
[16] Xilinx, "Optimal DDR4 System with Data Bus Inversion", DesignCon2016 非常好的DDR系統耗電分佈
[17] John Ellis (Synopsys), "Capturing (LP)DDR4 Interface PSIJ and RJ Performance", DesignCon2017.
[18] Hee-Soo Lee (Keysight), "Accurate Statistical-Based DDR4 Margin Estimation using SSN Induced Jitter Model", DesignCon2017. (推薦)
[19] Changwook (Intel), "In-depth Analysis of DDR3/DDR4 Channel with Active Termination", DesignCon2017.
[20] Billy Koo (Samsung), "Enabling World's first over 4.4Gbps/pin at sub-1V LPDDR4 Interface using Bandwidth Improvement Techniques", DesignCon2017.
[21] 3D IC Packaging, 3D IC Integration
[22] K. Shringarpure, S. Pan, "Innovative PDN Design Guidelines for Practical High Layer-Count PCBs", DesignCon2013. (推薦)
[23] Micron, "TN-00-33: Power Integrity Simulation with IBIS 5.0 Models", 2016
[24] DDR Fly-by vs. T topology
For DDR2 (T topology)
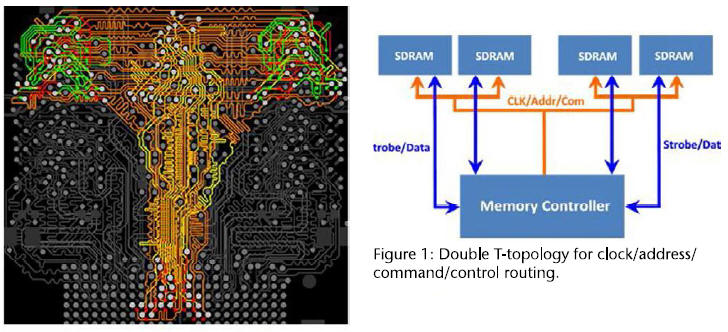
For DDR3 and 4 (Fly-by topology)